Volver al Blog
Inteligencia Artificial · Serie LLMs y n8n
2025-09-29 16:25:00
Arquitectura mínima para construir tu primer sistema con IA
Inteligencia Artificial · Serie LLMs y n8n
Arquitectura mínima para construir tu primer sistema con IA
No necesitas un ejército ni una nube exótica para empezar. Con una arquitectura mínima puedes lanzar un sistema útil, medible y seguro.
Objetivo
Definir una arquitectura simple, escalable y medible que soporte: preguntas y respuestas (RAG), extracción de datos y automatizaciones básicas.
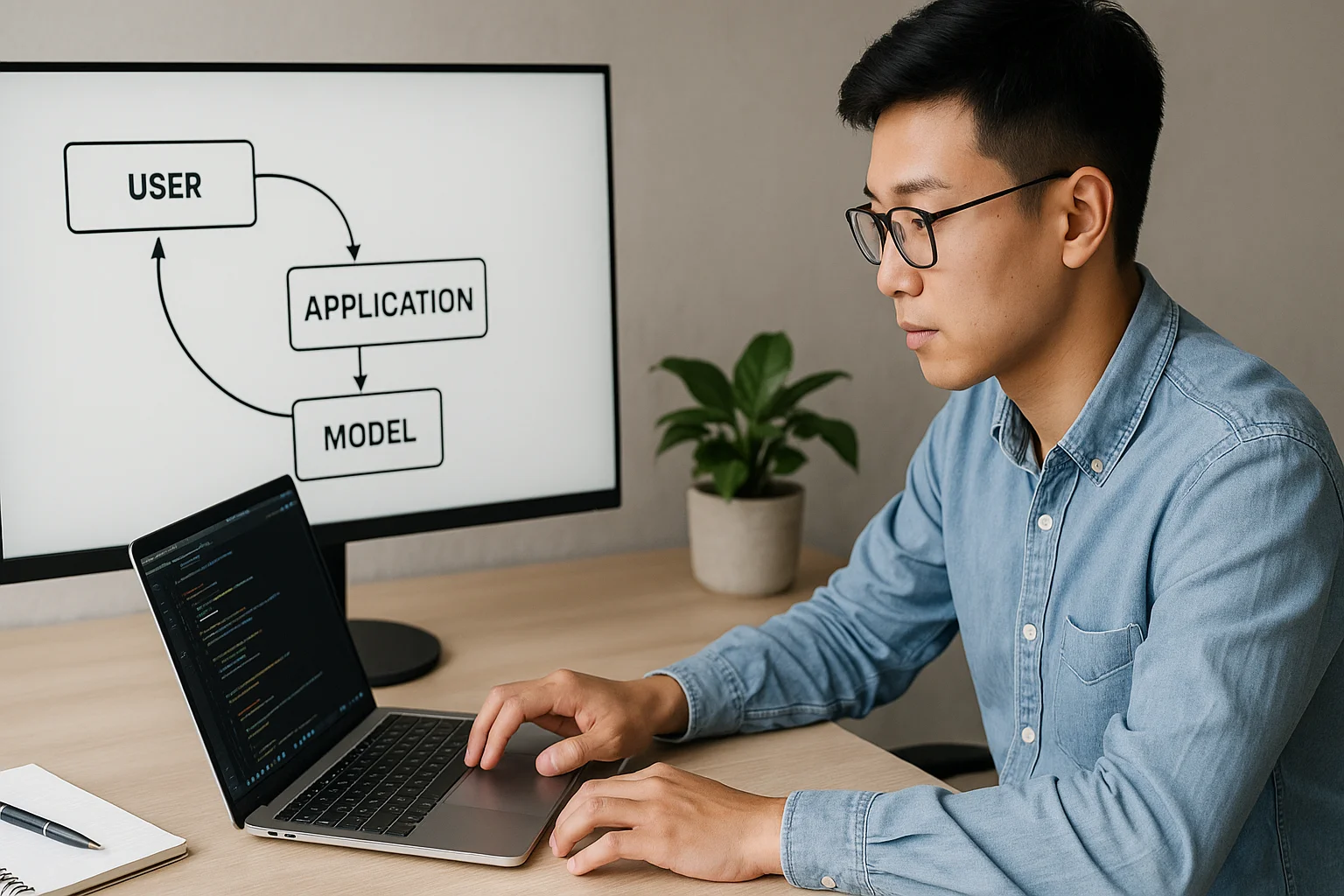
Componentes esenciales
- Frontend (web/app): UI que envía consultas y muestra resultados.
- API Laravel: endpoints, auth, validación y rate limits.
- Queue/Workers: ejecución asíncrona (Jobs para LLM/RAG).
- Vector Store: embeddings + metadatos para recuperación.
- Servicio LLM: proveedor elegido con métricas de uso.
- n8n: orquestador para webhooks, postprocesos y notificaciones.
- Observabilidad: logs, trazas, costos, latencias (p95).
- Base de datos: resultados, auditoría, permisos, historial.
Flujos básicos
- Q&A con RAG: Frontend → API → Job (recupera Top-K) → LLM → respuesta con citas → almacena trazas.
- Extracción: API → Job → LLM con schema JSON → validación → guarda entidad (ej. contactos/facturas).
- Automatización: evento (webhook/cron) → n8n → llama API/LLM → notifica por email/Slack.
Ambientes y despliegue
- Dev: llaves de prueba, logs verbosos.
- Staging: datos anonimizados, pruebas de carga.
- Producción: llaves separadas, políticas de rotación y backups.
Tip: usa variables .env para modelos, precios y límites (MAX_TOKENS, TOP_K, TIMEOUT_MS).
Seguridad y cumplimiento mínimo
- PII: desidentificar al ingresar; registra solo lo necesario.
- Permisos: tenancy/scoping por usuario/empresa.
- Guardrails: moderación de entrada/salida y whitelist de herramientas.
- Auditoría: guarda prompts, contextos y decisiones clave.
Costos bajo control
- Prompts compactos y max_tokens limitados.
- Top-K reducido con buenos filtros por metadatos.
- Caching de respuestas repetitivas y plantillas.
- Alertas si costo p95 excede umbral.
Micro-workflows en n8n
- QA Pipeline: Webhook → consulta vector store → LLM → formatea → Email.
- Alertas: Cron → lee métricas (DB) → IF p95/costo altos → notifica Slack.
- ETL semántico: Cron → descarga docs → chunking → embeddings → upsert.
Errores comunes
- Ignorar observabilidad (sin trazas, sin costos, sin p95).
- Meter documentos completos en lugar de fragmentos con metadatos.
- Sin desacople (todo en una misma request bloqueante, sin cola).
- Ambientes mezclados y llaves compartidas (riesgo alto).
Conclusión
Con esta arquitectura mínima lanzas rápido sin hipotecar el futuro. A partir de aquí, escala por cuellos de botella: recuperación, costos y latencia.
← Anterior: Agentes inteligentes: cuándo usarlos y cuándo evitarlos
Artículos Relacionados
Continúa explorando contenido similar.

Desarrollo web y programación
Las tendencias más recientes en el desarrollo web: Innovación y Creatividad en la Era Digital
Leer artículo
Medicina Digital: La Nueva Revolución Sanitaria
Inteligencia artificial en diagnósticos: el salto de la intuición al dato
Leer artículo


Inteligencia Artificial · Serie LLMs y n8n
Evaluación continua: asegurando que tu modelo no empeore con el tiempo
Leer artículo
Inteligencia Artificial · Serie LLMs y n8n
Del notebook al producto: llevando tu proyecto de IA a producción
Leer artículo



Medicina Digital: La Nueva Revolución Sanitaria
Blockchain médico: la era de la seguridad y trazabilidad absoluta
Leer artículo

Salud Preventiva y Análisis de Datos
Cómo la IA puede predecir infartos, cáncer y Alzheimer antes de que aparezcan
Leer artículo

Inteligencia Artificial · Serie LLMs y n8n
Mapa mental de la Inteligencia Artificial moderna
Leer artículo
Medicina Digital: La Nueva Revolución Sanitaria
Automatización de procesos clínicos: qué tareas dejarán de hacer los médicos
Leer artículo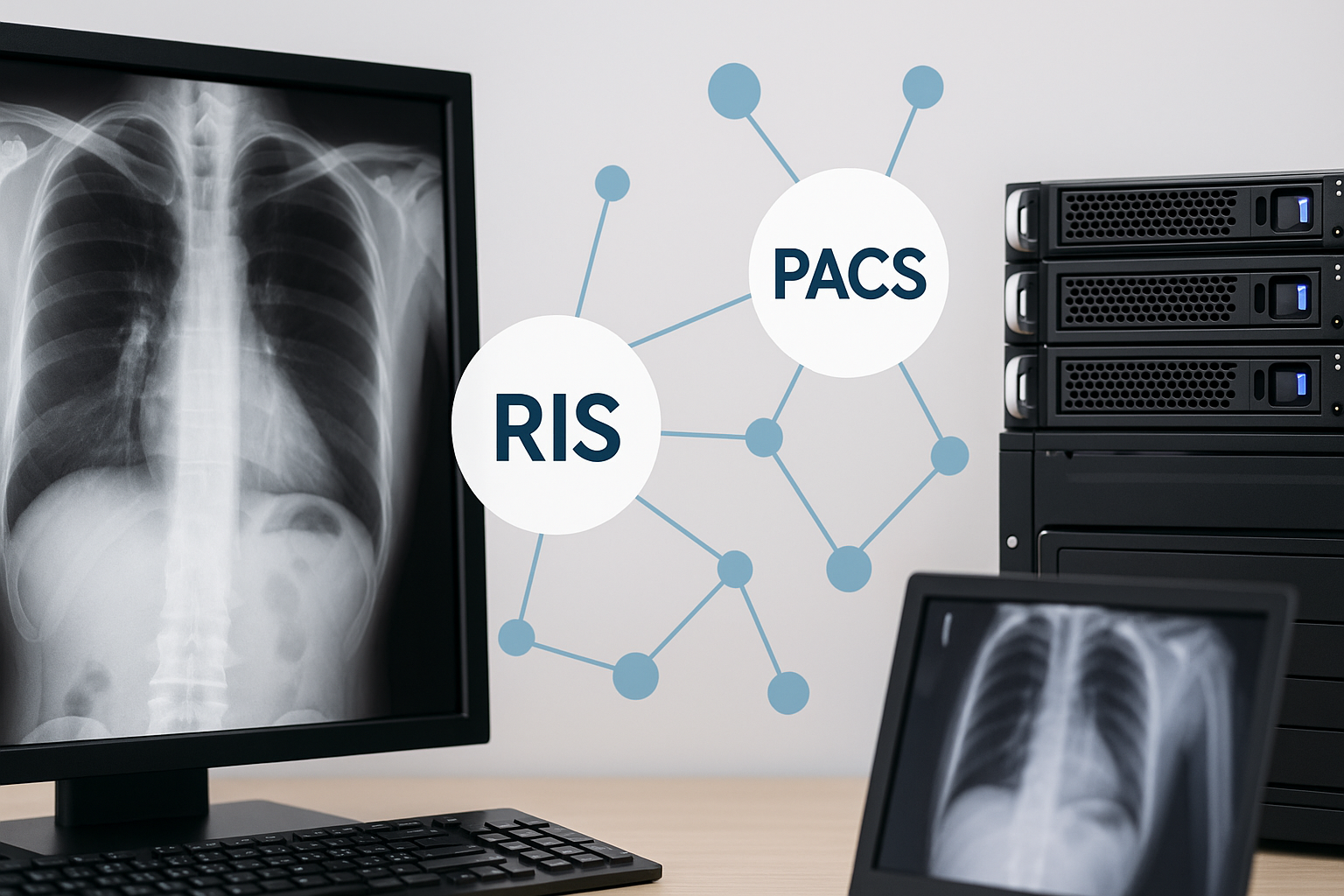
Imágenes Médicas e Inteligencia Diagnóstica
PACS y RIS: el sistema nervioso de la radiología moderna
Leer artículo
Inteligencia Artificial · Serie LLMs y n8n
Cómo detectar y manejar alucinaciones en modelos de lenguaje
Leer artículo

Medicina Digital: La Nueva Revolución Sanitaria